
Оригинал статьи доступен по ссылке.
Майкл Бибер
Йинг Ву колледж вычислительной техники
Технологический институт Нью-Джерси
Университет Хейста, Ньюарк, Нью-Джерси 07102 США
Аннотация
Мы используем двухэтапный подход к разработке приложений для Всемирной паутины. Сначала инженер-программист выполняет анализ взаимосвязи-навигации, анализируя существующее или новое приложение конкретно с точки зрения его внутренних связей и взаимосвязей. Это приводит его или ее к тому, чтобы лучше понять сложность и насыщенность программы, а также обеспечить доступ и метазнания желания пользователей. Во-вторых, динамический гипермедийный движок (DHymE) автоматически генерирует ссылки для каждой из этих взаимосвязей и элементов метазнания во время выполнения, а также сложные методы навигации, которые не часто встречаются в Интернете (например, экскурсии, обзоры, структурный запрос) поверх этих ссылок. Ссылки и навигация, а также функции аннотаций дополняют основную функциональность приложения.
Мотивация
По мере взросления Всемирной паутины и инструментов ее программирования, мы все чаще находим аналитические приложения с веб-интерфейсами и другими веб-сайтами с контентом, созданным вручную. Это включает в себя большой класс устаревших систем, организации которых спешат преобразоваться в веб-интерфейсы [Be95]. В этих документах рассмотрены вопросы разработки приложений для всех таких систем. Это также устраняет опасность того, что разработчики наделят эти системы скудостью ссылок вместо того, чтобы украшать их богатым слоем ссылок и навигационных возможностей, которые могли бы поддерживать интернет [BV97].
Кроме того, разработчики этих аналитических приложений часто сталкиваются с необходимостью представлять сложную информацию таким образом, чтобы пользователи могли лучше ее понять. Часто разработчики будут полагаться на проницательные методы визуализации и хороший дизайн пользовательского интерфейса. Эти подходы не являются тривиальными, и для некоторых приложений не могут передать информацию достаточно просто для всех пользователей, особенно студентов, новичков и тех, кто не знаком с низкоуровневыми деталями области приложения (например, нетехнического менеджера, который должен принимать решения на основе работы разработчика). Даже для приложений с простым отображением информации у пользователей могут возникать вопросы о том, что означает конкретный элемент, или как он был определен. Логически каждый элемент в веб-приложении может рассматриваться как потенциальная отправная точка для исследования информации. Возможность более подробно изучить часть информации может помочь пользователям разрешить сомнения или просто лучше понять, как этот элемент, так и анализ или отображение частью которого он является. Пользователи могут захотеть глубже изучить значения данных и символы, которые они видят, метки на графиках или пользовательских формах ввода, параметры во всплывающих списках, информацию, которую пользователи вводят в качестве ввода (перед фактической отправкой), или даже в командах меню, и других элементах управления, которые они могут вызвать.
Чтобы усложнить работу разработчика, пользователи часто имеют разные ментальные модели приложения (и его основной области), чем разработчик (аналитик приложения или инженер-разработчик). Даже когда разработчики работают в тесном контакте с пользователями, конечный результат может быть не одинаково интуитивным для всех пользователей или одинаково хорошо обслуживать индивидуальные задачи каждого пользователя. Пользователь может пожелать получить доступ к определенному отображению, функции или части информации, которая, по его мнению, имеет непосредственное отношение к поставленной задаче, но которую система не делает доступной с текущего экрана или в непосредственной близости.
Одной из главных целей гипермедиа является предоставление ссылок, представляющих отношения приложений, которые дают пользователю доступ к тому, что он хочет. Мы используем двухэтапный подход к разработке приложений для Всемирной паутины. Сначала разработчик выполняет анализ взаимосвязи-навигации, анализируя существующее или новое приложение конкретно с точки зрения его внутренних — и взаимосвязей. Это приводит его или ее к лучшему пониманию сложности и богатства программы, а также обеспечивает доступ и метазнания пользовательского желание. Во-вторых, динамический гипермедийный движок (DHymE) автоматически генерирует ссылки для каждой из этих взаимосвязей и элементов метазнаний во время выполнения, а также сложные методы навигации, которые не часто встречаются в Интернете (например, экскурсии, обзоры, структурный запрос) поверх этих ссылок. Ссылки и навигация, а также функции примечаний дополняют основную функциональность приложения [BK95, Bi98].
Анализ взаимосвязи и навигации
Метод взаимосвязи-навигационного анализа (Relationship-Navigation Analysis /RNA) состоит из 5 шагов:
- Анализ заинтересованных сторон
- анализ элементов
- взаимосвязь и анализ метазнания
- анализ навигации
- анализ реализации взаимосвязи и метазнаний
RNA имеет две основные цели. Сам по себе, анализ отношений поможет разработчику сформировать более глубокое понимание приложения. Это происходит главным образом в шагах 1-4. Затем разработчик должен решить, какие из этих отношений следует реализовать. Некоторые из них могут принести лишь незначительную пользу. Другие могут быть очень дорогостоящими или трудноосуществимыми. Эти решения принимаются на последнем этапе.
В то время как весьма полезно в его нынешней форме, мы намерены развивать технику RNA дальше, производя конкретные принципы для каждого шага и за счет сокращения диапазона вариантов, которые разработчик должен рассмотреть в рамках шагов анализа 2 и 3. Эти уточнения должны сделать анализ более систематическим и легким для осуществления, в то же время позволяя ему оставаться открытым.
Шаг 1: Анализ заинтересованных сторон
Целью анализа заинтересованных сторон является определение аудитории приложения. Знание того, кто будет заинтересован в приложении, помогает разработчику широко определить весь спектр важных элементов и связей, а затем сосредоточиться именно на них. Это особенно актуально для тех приложений, которые имеют общий доступ к Интернету, имеют гораздо более широкий круг заинтересованных сторон, чем многие себе представляют. Многие разработчики, по сути, считают эту часть RNA самой просвещающей. Разработчик также должен определить и понять задачи, которые каждый тип пользователя будет выполнять в приложении. Это поможет разработчику сосредоточиться на конкретных областях во время последующих шагов RNA.
Шаг 2: Элементный анализ
Здесь разработчик перечисляет все потенциальные элементы, представляющие интерес для приложения. На одном уровне к ним относятся все типы элементов, отображаемых на любом интерактивном дисплее (информационные экраны, формы, документы и любые другие типы отображения), а также экраны, формы и сами документы. Самый простой способ начать – изучить каждый экран (или макет) и определить каждое значение и пометить его. Обратите внимание, что разработчик должен определять виды или классы элементов, а не отдельные экземпляры. Типы отношений, которые мы обсуждаем на шаге 3, относятся к определенным типам элементов. Например, в области анализа решений к ним относятся «модель» и «значение данных » в отличие от конкретных моделей или значений данных.
Шаг 3: Анализ взаимосвязи
Анализируются взаимоотношения взаимоотношения, внутривидовые отношения и метазнания. Разработчик должен рассмотреть каждый элемент интереса, выявленных в предыдущем этапе, с точки зрения каждого из видов отношений, для каждой группы заинтересованных сторон. Определенные отношения будут полезны только определенным заинтересованным сторонам, и механизм гипермедиа будет фильтровать их. Связи могут приводить к информации внутри и вне приложения. Разработчики не должны чувствовать себя ограниченными реальными соображениями доступности, затратами или усилиями на реализацию. На этом этапе они должны максимально полно проявить свои творческие способности. Только на шаге 5, они должны решить, как реализовать обнаруженные отношения и метазнания.
RNA в настоящее время помогает разработчикам определить следующие типы отношений и метазнания в приложении: схема, процесс, операция, структурные, описательные, параметрические, статистические, отношения совместной работы и упорядочения. [Bi98] дает более подробную информацию для каждого. Бибер и Витали [BV97] показывают, как некоторые из этих общих типов отношений могут дополнять онлайновый счет продажи. [Bi98] показывает, как они могут дополнять систему поддержки принятия решений математического моделирования.
Шаг 4: Анализ навигации
После того, как мы определим отношения, мы можем думать о том, как пользователь может получить к ним доступ. Наиболее простая реализация сделает каждое отношение ссылкой, а затем обеспечит простой обход (пользователи, выбирающие якорь и ссылку, и система, отображающая назначение ссылки). Но некоторые типы отношений поддаются более сложной навигации. Концепция гипермедиа включает в себя множество других навигационных функций, основанных на связях или ссылках. К ним относятся экскурсии и маршруты, обзоры и структурный запрос [BVA97, Ni95]. На этом этапе РНК разработчик должен решить, какие функции навигации могут наилучшим образом удовлетворять потребности заинтересованных сторон.
Шаг 5: анализ реализации взаимосвязи и навигации
Очевидно, что Шаг 3 может генерировать много отношений, а Шаг 4 может генерировать много возможных навигационных возможностей. На этом этапе разработчик должен решить, какие из них следует реализовать. Этот шаг не является фактической реализацией, а просто логическим решением, какие отношения следует реализовать. Разработчики должны учитывать затраты и выгоды (фактические и предельные) как реализации, так и отображения каждого этапа. Мы отделяем этот шаг от шагов 3 и 4, чтобы разработчик мог реализовать все свои творческие таланты без ограничений по соображениям реального мира. Затем конструктор создает правило сопоставления (в указанном формате) для каждой из реализуемых связей. Правила сопоставления определяют команды или алгоритмы поиска конечной точки каждой связи.
DHymE (Dynamic Hypermedia Engine)
Dhyme hypermedia engine выполняется отдельно от целевого приложения. Мы пишем программу-оболочку для каждого приложения, чтобы интегрировать его в архитектуру нашего движка. Затем приложения или их оболочки подключаются к DHymE через прокси-сервер. DHymE перехватывает все сообщения, передаваемые между приложением и пользовательским интерфейсом, и использует указанные выше правила для сопоставления каждого соответствующего элемента сообщения узлу гиперсреды или якорю. Наша оболочка веб-браузера интегрирует эти якоря в отображаемый документ и передает его через прокси-сервер в веб-браузер пользователя. Когда пользователь выбирает якорь, оболочка браузера передает его DHymE, который возвращает список возможных ссылок (по одному для каждого соответствующего отношения, как определено правилами сопоставления). Если пользователь выбирает обычную команду приложения (сопоставленную ссылке операции), DHymE передает команду приложению для обработки. Если пользователь выбирает ссылку на движок гиперсреды (например, для создания аннотации), DHymE обрабатывает ее полностью. Если пользователь выбирает дополнительную схему, процесс, операцию, структурное, описательное, или информационное вхождение отношения, DHymE выводит соответствующие команды приложения, операции мета-приложения (например, на уровне операционных систем или на уровне схемы) или операции гипермедиа движка, который будет производить необходимую информацию. Если пользователь выбирает созданную пользователем аннотацию, DHymE извлекает ее. Таким образом, DHymE автоматически обеспечивает все перелинковки (а также навигацию) с приложениями, которые остаются не знающими гипермедиа и на самом деле часто полностью неизменными. В настоящее время мы интегрируем несколько приложений с DHymE, автоматически предоставляя каждому веб-интерфейс или дополняя его существующий веб-интерфейс: систему отслеживания заявок на персонал, систему управления связанными базами данных, систему управления математической моделью, систему анализа транспортных электронных таблиц и инструмент анализа поддержки принятия решений с несколькими критериями. [Bi98] описывает эти идеи и более старые, а также не-веб прототип DHymE более подробно. [Bi97, CB97] предоставляет некоторые сведения о движке.
Вывод
Мы надеемся, что наш наиболее весомый вклад будет заключаться в том, чтобы убедить разработчиков веб-приложений (как новых, так и перенесенных из других компьютерных сред) в полной мере использовать возможности компоновки в своих приложениях. Снова и снова дизайнеры говорят нам, что RNA показала им ссылки, которые они никогда не представляли в своих приложениях. Их выявление является необходимым первым шагом на пути к имплементации моделей. Реализованные продуманно, веб-ссылки и навигационные средства могут пройти долгий путь к снижению сложности приложений для пользователей. RNA предоставляет разработчикам инструмент для определения возможностей дополнительной компоновки в приложениях. DHymE hypermedia engine автоматически генерирует эти ссылки, практически без изменений в приложении.
Благодарность
Выражаем признательность за финансирование данного исследования аспирантской программе факультета JOVE NASA, Центру мультимедийных исследований в Нью-Джерси, Национальному центру транспорта и промышленной производительности в Нью-Джерси Технологическому институту (NJIT), Департамент транспорта Нью-Джерси, Комиссии по науке и технологии Нью-Джерси, а также грантам фондов Слоана и AT&T, и программе NJIT SBR.
Ссылки на литературу
- [Be95] Беннет К. Системы наследия: справляясь с успехом. Программное обеспечение IEEE, январь 1995, 19-23.
- [Bi97] Бибер, М., Гипертекстовый движок: поддержка вычислительных приложений, Техническое примечание, 1997.
- [Bi98] Бибер, М., Дополнение заявок Гипермедиа, Техническая записка, 1998.
- [BK95] Бибер, М. Качмар К. Проектирование гипертекстовой поддержки вычислительных приложений. Сообщения АСМ 38 (8), 1995, 99-107.
- [BV97] Бибер М. Витали Ф. (1997). К поддержке гипермедиа во Всемирной паутине. IEEE Computer 30 (1), 1997, 62-70.
- [BVA97] Бибер, м., Витали, Ф., Ашман, Х., Баласумарян В. и Ойнас-Кукконен, H. Гиперсреда четвертого поколения: некоторые недостающие ссылки для Всемирной паутины. Международный журнал компьютерных исследований человека 47, 1997, 31-65.
- [CB97] Чиу, С. и Бибер, М., Универсальное динамическое сопоставление обертка для открытой гипертекстовой системы поддержки аналитических приложений, Hypertext’97 Proceedings ‘ 97, АСМ Press, Нью-Йорк, Нью-Йорк, апрель 1997 года, 218-219.
[Ni95] Ниельсен Дж. Мультимедиа и гипертекст: Интернет и не только. AP Professional, 1995.










 Его цель состоит в том, чтобы обеспечить численное вычисление с функциями. Мой интерес и вклад в систему наиболее заметен в решении обыкновенных и (1+1 мерных) дифференциальных уравнений в частных производных. Используя знакомый синтаксис MATLAB, такой как \ и eigs, решения краевых или собственных задач могут быть получены с полной числовой точностью автоматически.
Его цель состоит в том, чтобы обеспечить численное вычисление с функциями. Мой интерес и вклад в систему наиболее заметен в решении обыкновенных и (1+1 мерных) дифференциальных уравнений в частных производных. Используя знакомый синтаксис MATLAB, такой как \ и eigs, решения краевых или собственных задач могут быть получены с полной числовой точностью автоматически. конформными отображениями областей, ограниченных полигонами, включая неограниченные области, логические четырехугольники и каналы. Он включает в себя модуль для решения уравнения Лапласа в таких областях с кусочно-постоянными граничными условиями, до десяти и более цифр в секундах. Почти все функции Toolbox доступны через графический интерфейс.
конформными отображениями областей, ограниченных полигонами, включая неограниченные области, логические четырехугольники и каналы. Он включает в себя модуль для решения уравнения Лапласа в таких областях с кусочно-постоянными граничными условиями, до десяти и более цифр в секундах. Почти все функции Toolbox доступны через графический интерфейс. листья обычно имеют едкий запах. Вербена – как цветы образуются в кластерах из пазух листьев или на концах ветвей. Мелкие, ягодообразные плоды содержат семена. В некоторых регионах, включая Техас, лантаны растут дикими, как сорняки, в основном распространяемые птицами, которые очень любят их сочные плоды. Названия видов на родном l. horrida, относится к резкому запаху опалых листьев.
листья обычно имеют едкий запах. Вербена – как цветы образуются в кластерах из пазух листьев или на концах ветвей. Мелкие, ягодообразные плоды содержат семена. В некоторых регионах, включая Техас, лантаны растут дикими, как сорняки, в основном распространяемые птицами, которые очень любят их сочные плоды. Названия видов на родном l. horrida, относится к резкому запаху опалых листьев.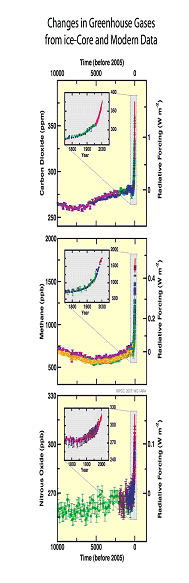 в настоящее время хорошо документировано и принято учеными как факт. Группа экспертов, созванная Национальным исследовательским советом США, ведущим научным политическим органом страны, в июне 2006 года выразила «высокий уровень уверенности» в том, что Земля является самой горячей, по крайней мере, за 400 лет и, возможно, даже за последние 2000 лет. Исследования показывают, что средняя глобальная температура поверхности увеличилась примерно на 0,5-1,0°F (0,3-0,6°C) за последнее столетие. Это самый большой рост температуры поверхности за последние 1000 лет, и ученые предсказывают еще больший рост за это столетие. Это потепление в значительной степени объясняется увеличением выбросов парниковых газов (в первую очередь углекислого газа и метана) в верхних слоях атмосферы Земли, вызванных сжиганием человеком ископаемых видов топлива, промышленной деятельностью, сельским хозяйством и обезлесением.
в настоящее время хорошо документировано и принято учеными как факт. Группа экспертов, созванная Национальным исследовательским советом США, ведущим научным политическим органом страны, в июне 2006 года выразила «высокий уровень уверенности» в том, что Земля является самой горячей, по крайней мере, за 400 лет и, возможно, даже за последние 2000 лет. Исследования показывают, что средняя глобальная температура поверхности увеличилась примерно на 0,5-1,0°F (0,3-0,6°C) за последнее столетие. Это самый большой рост температуры поверхности за последние 1000 лет, и ученые предсказывают еще больший рост за это столетие. Это потепление в значительной степени объясняется увеличением выбросов парниковых газов (в первую очередь углекислого газа и метана) в верхних слоях атмосферы Земли, вызванных сжиганием человеком ископаемых видов топлива, промышленной деятельностью, сельским хозяйством и обезлесением. масштабы влияния Солнца на климат Земли не были изучены достаточно хорошо. Однако с начала 1990-х годов были проведены обширные исследования для определения роли Солнца в глобальном потеплении или изменении климата.
масштабы влияния Солнца на климат Земли не были изучены достаточно хорошо. Однако с начала 1990-х годов были проведены обширные исследования для определения роли Солнца в глобальном потеплении или изменении климата. Солнечные излучения были надежно измерены спутниками только на 30 лет. Эти точные наблюдения показывают изменения в несколько десятых процента, которые зависят от уровня активности в 11-летнем солнечном цикле. Изменения за более длительные периоды должны быть выведены из других источников. Оценки более ранних изменений важны для калибровки климатических моделей. Хотя один из компонентов недавнего глобального изменения климата, возможно, был вызван повышенной солнечной активностью последнего солнечного цикла, этот компонент был очень мал по сравнению с воздействием дополнительных парниковых газов. Согласно
Солнечные излучения были надежно измерены спутниками только на 30 лет. Эти точные наблюдения показывают изменения в несколько десятых процента, которые зависят от уровня активности в 11-летнем солнечном цикле. Изменения за более длительные периоды должны быть выведены из других источников. Оценки более ранних изменений важны для калибровки климатических моделей. Хотя один из компонентов недавнего глобального изменения климата, возможно, был вызван повышенной солнечной активностью последнего солнечного цикла, этот компонент был очень мал по сравнению с воздействием дополнительных парниковых газов. Согласно 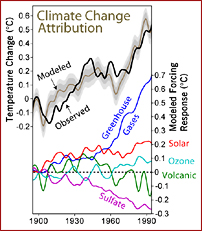 Межправительственная группа экспертов Организации Объединенных Наций по изменению климата изучает глобальное потепление в течение многих лет. Их последний доклад, вышел в феврале 2007 года (см.
Межправительственная группа экспертов Организации Объединенных Наций по изменению климата изучает глобальное потепление в течение многих лет. Их последний доклад, вышел в феврале 2007 года (см.