Автор оригінала статті — Miss Eleanor Krawitz.
Протягом недавніх років видатні успіхи були здійснені у всіх областях наукових досліджень і важливим фактором в цьому прогресі було використання автоматичних обчислювальних методів та обладнання. Сьогодні розрахунки виконуються автоматично в лабораторіях по всій країні.
Розробка цих обчислювальних лабораторій становить особливий інтерес Колумбійських студентів з тих пір, як одні з найбільш ранні установи були встановлені тут в Університеті. Статистичне Бюро Колумбійського Університету було засноване в кінці двадцятих століть для використання педагогами і статистами. Астрономічне Бюро засноване в 1934. Ним керував доктор В. Дж. Екерт (W. J. Eckert). Воно працювало спільно з Колумбійським Університетом, Американським Астрономічним Співтовариство, і корпорацією Міжнародні машини для бізнесу (International Business Machines), і функціонувало як некомерційна організація куди астрономи зі всього світу могли прийти щоб виконати свій розрахунки.
У 1945 компанія ІВМ створила Департамент Наукових Дисциплін, куди доктор Екерт був призначений в якості директора, і заснував Науково-обчислювальну Лабораторію Уотсон (Watson Scientific Computing Laboratory) в кампусі Університету.
Головна мета Лабораторії Уотсона – це дослідження різних галузей науки, особливо тих, які включають в себе математичні та числові обчислення. Послуги лабораторій люб’язно пропонують будь-якому вченому або студенту, що навчається, зайнятися дослідженнями, які роблять значний внесок у прогрес в галузях науки. Такі дослідження використовують обчислювальні машини для досягнення цієї мети. Щороку дві стипендії Лабораторії Уотсона по прикладній математиці присуджуються студентам, студії або дослідження яких включають в себе масштабні обчислення. Співробітники бібліотеки пропонують курси зі сфери своїх інтересів і це робиться під патронатом різних факультетів Університету.
Курси для аспірантів включають роботу і використання машин і обчислювальних методів; академічний кредит для курсів може бути отриманий через реєстрацією в Університеті звичним способом. Спеціальні класи по експлуатації машин представляються тут регулярно і доступні для професіоналів зі всього світу, які відвідують вчених. Також вони доступні для аспірантів, які працюють над вченим званням Доктора. Додаткова функція Лабораторії Уотсона — це поширення технічної інформації щодо математичних машинних методів і математичних таблиць. Тут доступна велика бібліотека, яка охоплює ці теми.
В багатьох галузях науки тут були успішно завершені дослідження, як співробітниками закладу, так і запрошеними вченими.
Дослідження були успішно завершені в лабораторії співробітниками та запрошеними вченими. Нижче наведений неповний список завершених робіт, а також тих, які знаходяться в прогресі:
- Астрономія: інтеграція орбіт планет і астероїдів,
- Геофізика: відстеження шляхів звукових хвиль під водою для різних глибин і напрямів,
- Оптика: розрахунки, які втілюють метод трасування променів,
- Хімія: обчислення квантово-механічних резонансних енергій ароматичних сполук,
- Інженерія: побудова таблиць обчислення розрахункових напружень та механізмів, пов’язаних із землетрусами
- Інжиніринг: побудова таблиць «Весна» та «Шестерні» та обчислення напруги, пов’язані з навантаженнями на землетрус,
- Економіка: оцінки певних коефіцієнтів у рівняннях економічних моделей, що використовують матричне множення і інверсії
- Фізика: обчислення ймовірності перехідності кальцію
- Кристалографія: оцінка Зміни Фур’є для структури інсуліну.
Лабораторія підтримує широке різноманіття, включаючи цифрові і аналогові типи машин. Цифрові машини займаються обчисленнями, в той час як аналогові машини виконують фізичні вимірювання. Ці комп’ютери розроблені для вирішення проблем у найбільш доцільний спосіб і порівняння різних методів вирішення для визначення найбільш ефективного.
Більшість машин зчитують і записують дані через використання перфокарти, яка постачає засоби обробки автоматично. Карти таким чином можуть бути оброблені через будь-яку серію калькуляторів і включають будь-яку бажану послідовність операцій, що виконуються на них. Основна перевага техніки перфокарт полягає в тому, що велика кількість схожих операцій можуть бути виконані у великій кількості. Після перфорацій вихідних значень на картах далі всі процедури відбуваються автоматично. Перфорація може знаходитися в будь-якому з восьми стовпчиків карти. Кожен стовпець поділяється на дванадцять окремих позицій, що представляють числа від 0 до 9, тоді як дві спеціальні перфоровані позицій позначені як Х та Y. Перфорація Х використовується в основному для призначення спеціальних операцій або від’ємного числа. Букви алфавіту записані двома перфораціями у колонці, комбінацією X, Y, чи 0, з якими цілими числами від 1 до 9 (дивитися рис. 1).

Рисунок 1. Табуляторная Карта, яка демонструє 12 позицій і комбінацій перфорацій для відображення букв.
У всіх машинах принцип зчитування карт однаковий. Отвори перфоровані через карту і зчитуються за допомогою електричного контакту, який проходить через отвори. Карта діє як ізолятор, що проходить між металевою щіткою і латунним роликом (дивитися Рис. 2).
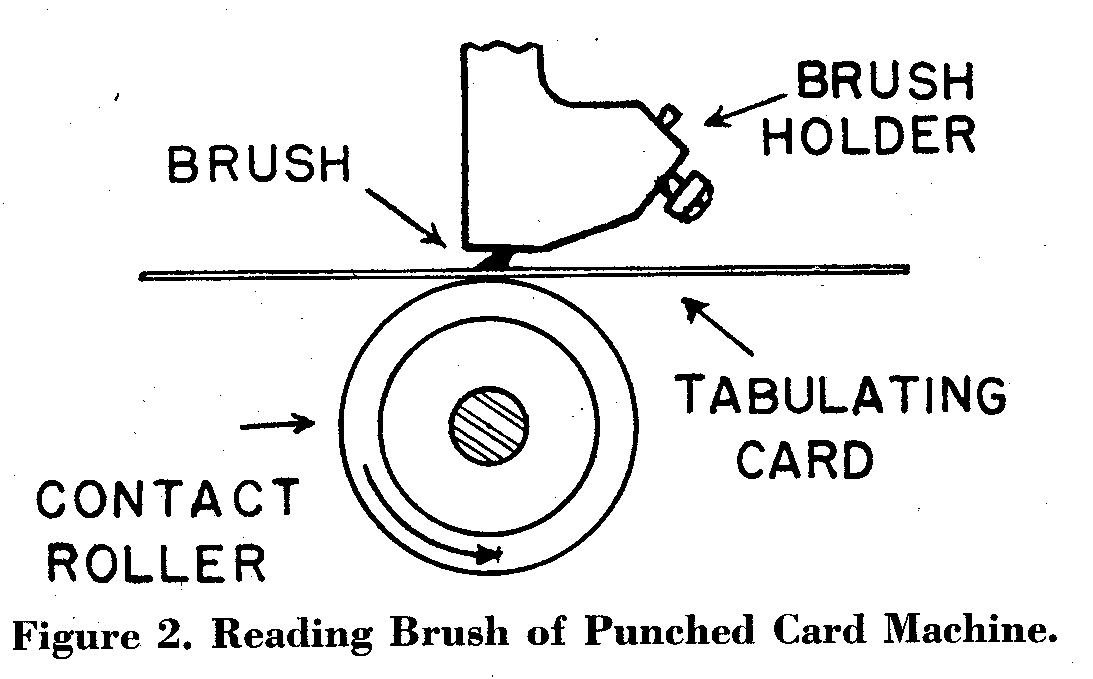
Отвір, перфорованої карти, пропускає контакт між щіткою і ролером, таким чином завершуючи електричну схему. Далі електричні імпульси роблять доступною зовнішню контрольну панель. Синхронізація імпульсів визначається позицією отворів в карті, а розрахунок часу імпульсів визначається позицією отворів в карті. Все функцій машини управляються напрямком цих імпульсів на контрольній панелі, і в результаті гнучкості цієї панелі, може бути виконана більша частина операцій.
Великий відсоток проблем, що зустрічаються в числових обчисленнях можуть бути продуктивно оброблені в стандартних машинах IBM. Перший крок підходу до цих проблем це переклад оригінальних даних на мову калькуляторів. Тобто слід записати ці дані у вигляді перфорованих отворів на стандартних картах. Це функція KeyPunch (клавішний перфоратор). Бажана інформація транскрибується в карту шляхом натискання кнопок машини у лінії з відповідною колонкою. Ці карти можуть бути включені в клавішний перфоратор вручну або автоматично. Після того як кожна колонка буде перфорована, карта автоматично досягає наступної позицій перфорацій. Числові перфоратори мають чотирнадцять клавіш; по одній для кожної з дванадцяти перфорованих позицій, клавіша пробілу, і клавіша вилучення картки. Алфавітні перфоратори крім того мають клавіатуру друкарської машинки, яка автоматичний перфорує два отвори в колонці. Тоді закодовані клавішним перфоратором карти, готові для вбудовування через будь-яку іншу машину, необхідну для вирішення проблеми.
Сортувальник використовується для організації перфорованих карт в будь-якій бажаній номерній та алфавітній послідовності в залежності від інформацій до них. Картки до сортування подаються з завантажувача до однієї щітки яка зчитує обрану колонку і сортує кожну карту в одну із тринадцяти зон. Тут є зона для кожної з дванадцяти перфорованих позицій і одна для порожніх стовпців. Завдяки успішному сортуванню, карти розташовуються в потрібному порядку. Машина, що працює зі швидкістю 450 карт в хвилину, обладнана лічильником для запису кількості оброблюваних карт.
Алфавітний інтерпретатор розроблений для переведення числової і буквеної інформацій на карті в друкований вигляд в будь-який з двох рядків у верхній частині карти. Таким чином перфокарта легше зчитується, і може бути використана як файлова карта, так само як і в машині.
Облікова машина — це високошвидкісна машина додавання і друку. Вона зчитує дату з карти, додає і віднімає їх в лічильниках, а також друкує на аркуші паперу інформацію з карти або повну інформацію з лічильників. Машина перераховує алфавітні і цифрові дані зі швидкістю вісімдесят карт за хвилину, або акумулює в цілому так багато як вісімдесят цифр в 150 картах за хвилину.
Відтворюючий перфоратор розшифровує всі дані, перфоровані в одному наборі карт, в інший набір, або копіює дані з однієї карти в групу детальних карт. Перфоратор має порівняльну одиницю, яка співставляє два набори даних і відображає будь-які відмінності між ними. Машина може бути адаптована для використання в якості Підсумовуючого перфоратора для запису на новій карті суми яка була зібрана в Обліковій машині.
Підбирач виконує деякі з функцій Сортувальника у більш ефективній манері. Він додає два набори карт разом, вибираючи конкретні картки в одну з чотирьох обраних зон, поєднуючи дві групи карт у відповідності з панеллю управління, і перевіряє послідовність групи карт. Машина дуже гнучка і допускає обробку карток відповідно до складних шаблонів з залученням порівняння двох контрольних цифр. Карти можуть проходити через Підбирач у кількості від 240 до 480 за одну хвилину.
Електронні розрахункові перфоратори — це високошвидкісна машина, яка використовує електронні схеми для виконання базових операцій. Це додавання, віднімання, множення і ділення чисел на введеній карті, і перфорація відповідей в тій же карті або наступній. Він виконує ці операцій повторно і в будь-якому порядку за долю секунди. Розрахунковий перфоратор зчитує коефіцієнт перфорацій на карті, і виконує додавання, віднімання, множення і ділення, в будь-якій необхідній послідовності. Окремі результати можуть бути перфоровані для кожного типу розрахунку, або результати можуть зберігатися і використовуватися як коефіцієнт для наступних розрахунків. Ця машина розраховує восьмий порядок обчислення різниці з одинадцятирозрядною функцією і безліччю складних рівнянь із залученням великої кількості операцій.
На додачу до стандартних машин, розглянутих вище, в лабораторії є ряд спеціально сконструйованих калькуляторів, які управляються за допомогою релейних мереж і електронних схем. Нижче короткий опис цих спеціальних машин.
Релейний калькулятор виконує всі базові арифметичні операції, включаючи визначення квадратного кореня через складні релейні мережі. Він надзвичайно гнучкий, завдяки великому обсягу внутрішньої пам’яті, швидкості виконання обчислень, його здатності одночасно зчитувати чотири карти і перфорувати п’яту, а також за рахунок його потужності для оперування великими і різноманітними програмами.
Ця машина обладнана схемою зіставлення для полегшення операцій у вигляді таблиць. Величезна кількість складних проблем були вирішені на Релейному калькуляторі, включаючи множення гармонійних серій, множення матриць, і шостому порядку диференційних рівнянь.
Картковий калькулятор послідовності складається з: Обчислювальної машини, яка зчитує, додає, віднімає, і запам’ятовує дані; Сумарного Перфоратора, який перфорує фінальні значення ;релейної коробки для забезпечення гнучкості контролю операцій; блоку, який виконує множення і ділення. Операції в інших калькуляторах зазвичай програмуються через проводку на контрольній панелі. Зараз ця машина має по суті один комплект базової контрольної панелі і він управляється кодовими перфораціями на карті. Цей калькулятор був перевірений зокрема в майстерних обчисленнях орбіт астероїдів.
Обчислювач лінійних рівнянь — це електричний девайс для одночасного розв’язання лінійних рівнянь включно до дванадцятого порядку. Після того як коефіцієнти були встановлені на циферблатах, перемикачах, або перфокартах, до отримання рішення задаються різні змінні. Це один із методів рішення який дає дуже швидку конвергенцію. Ця машина була сконструйована в лабораторії Роберта М Волкера (Robert M. Walker), нашими співробітниками і професором Френсісом Дж. Мюрреєм (Francis J. Murray) з математичного відділення Університету.
Контрольно-вимірювальна машина з картковим управлінням призначена в першу чергу для вимірювання астрономічних знімків. Незважаючи на це, він може бути легко застосовуватись для роботи з фотографіями в будь-якій сфері. Тут використовується пластина фотокартки з частиною неба включаючи зірки введені в машину разом з перфокартою, що показує наближені координати зірок. Машина тоді автоматичний зчитує перфокарту, локацію зірок на пластині фотокартки з наближених координат, точно вимірюючи їх позицій, і записує ці вимірювання на карті. Запис перфокарти потім доступний для математичної обробки.
З самого початку існування Астрономічного Бюро в 1934 році, декілька інших лабораторій перфокарт були запущені в індустрії та управлінні. Ці лабораторії у військові періоди відіграли вирішальну роль в операціях нашої національної оборонної програми. В цій групі були: Лабораторія Балістичних Досліджень в Абердині, Меріленді і Дальгрені, Вирджинія (Aberdeen, Maryland and Dahlgren, Virginia). У тій же самій категорій була Військово-морська Обсерваторія Сполучених Штатів, яка готувала астрономічні таблиці для використання в повітрі і в морській навігації, астрономії і геодезії. В індустрії обчислювальні лабораторії відіграли значну роль в дослідженнях як чистої, так і прикладної науки. Техніки перфокарт використовувалися, наприклад, для вирішення проблем пов’язаних з аналізом напруг і деформацій конструкцій повітряних суден і вібраційного аналізу великого обладнання.
Ілюстрація застосування обладнання перфокарт у проблемах, що виникають у промисловості в дизайні і конструкціях суден, де необхідно вказувати точне місце розташування великої кількості точок на поверхні. Дизайнер може зробити це, враховуючи різні поперечні перерізи корпусу і представляючи контур кожного з цих розділів многочленом, скажімо, п’ятого ступеня (див. Рис3).
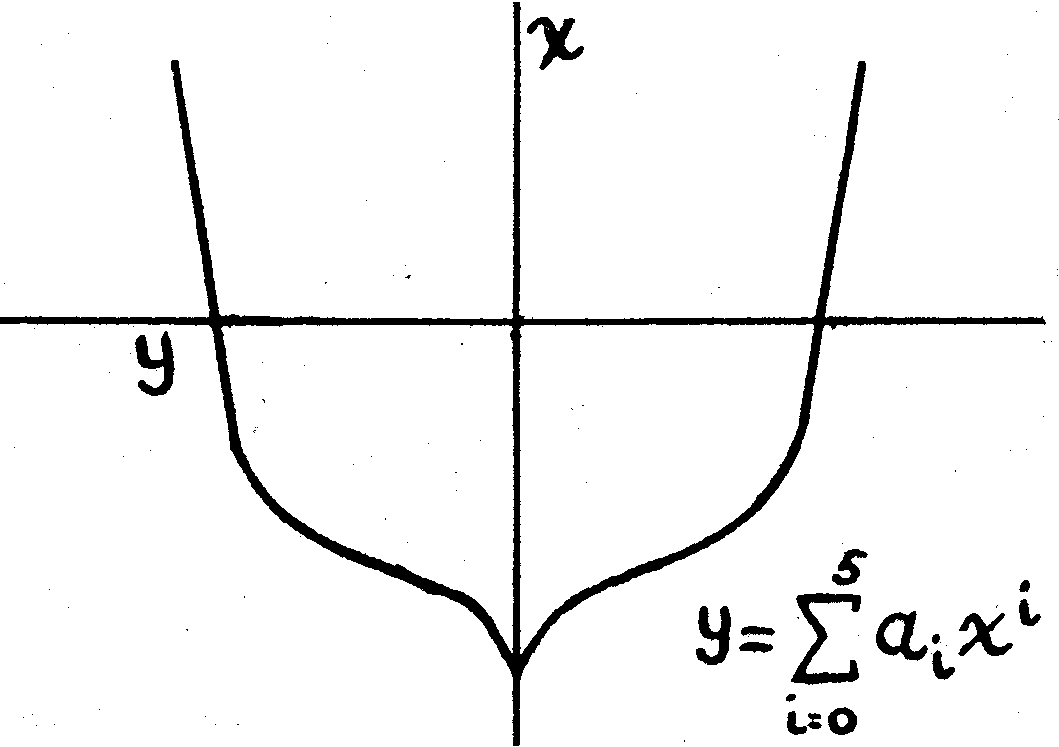
Рис. 3. Поперечне січення через судно
Значення констант,a0, …, a5, в рівнянні буде змінюватись з кожною обраною секцією, через кривизну поверхні в поздовжніх напрямках. Тому, якщо судно розділене на 200 поперечних перерізів, і необхідно визначити 100 точок з кожного боку корпусу для кожного поперечного перерізу, многочлен повинен бути оцінений 20, 0000 раз. Використання обладнання перфокарт для рішень цієї проблеми переводить дуже громіздку роботу в ту яка обчислюється автоматичний машиною після завершення початкового планування.
***
Міс Елеанор Кравіц, яка проводить відмінності будучи першою жінкою автором робить внесок в щоквартальний журнал COLUMBIA ENGINEERING QUARTERLY, може пишатися іншими видатними здобутками. Вона закінчила Вищу Бруклінську школу Самуеля І. Тільдена (Brooklyn’s Samuel I. Tilden High Schoo) у 1943 році, де вона була членом шкільного почесного співтовариства «Аріста». В Бруклінському Коледжі вона була хранителем PiMuEpsilon, почесного Математичного співтовариства, поки не отримала ступінь бакалавра з математики в 1947 році. Тоді вона працювала в якості вчителя на заміну в Середній школі Мідвуда і в її Альма-матер, Старшій Школі Тильдена. Але незабаром Елеанор почала викладацьку кар’єру в середній школі, щоб отримати ступінь магістра з математики в Колумбії.
Сьогодні міс Кравіц – керівник відділу Табулювання в I. B. M., Обчислювальній Лабораторій імені Томаса Дж. Уотсона при Колумбійському Університеті . Вона не тільки інструктує клас з астрономії у Вищій школі по роботі комп’ютерів, а ще й займається обчисленнями для вирішення проблем у фізиці, математиці й астрономії.
Автор: Елеонора Кравіц Колчин, листопад 2003 року.
Інші статті автора:
- Krawitz, Eleanor, «Punched Card Mathematical Tables on Standard IBM Equipment», Proceedings, Industrial Computation Seminar, IBM, New York (Sep 1950), pp.52-56.
- Krawitz, Eleanor, «Matrix by Vector Multiplication on the IBM Type 602-A Calculating Punch», Proceedings, Industrial Computation Seminar, IBM, New York (Sep 1950), pp.66.70
- Green, Louis C., Nancy E. Weber, and Eleanor Krawitz, «The Use of Calculated and Observed Energies in the Computation of Oscillator Strengths and the f-Sum Rule» Astrophysical Journal, Vol.113 No.3 (May 1951), pp.690-696.