Оригинал доступен на сайте zisman.ca
Обзор Claris Works 1.0 для Windows
Алан Зисман (c) 1994. Впервые опубликовано в Our Computer Player 18 марта 1994 года.
Для множества людей — еще на заре персональных компьютеров — запуск интегрированной программы AppleWorks от Apple Computer на компьютере Apple II оказался хорош, как только появился.
Представьте себе… текстовую обработку, электронную таблицу и базу данных. Все в одном приложении. В более поздних версиях, таких как AppleWorks GS, было добавлено привлекательную поддержку графики и мыши.
Но на собственном Apple Macintosh и на ПК с DOS, недорогие интегрированные пакеты, в конечном итоге, стали подразумевать один продукт: Microsoft Works. Конечно, существовали и другие интегрированные программы… дорогие, такие как Lotus Symphony или Ashton-Tate Framework, либо же недорогие, как PFS-Works или Alpha Works (позже Lotus Works) для ПК либо Symantec Great Works или Beagle Works (теперь из Word Perfect) для Mac. Но похоже, что на обеих платформах в этой категории программного обеспечения доминировал Microsoft.
До недавнего времени это так. Наконец, отдел программного обеспечения Apple Claris нанес ответный удар своим рейтинговым Claris Works, борющимся за первое место в плане продаж и что имеет решающее значение относительно платформе Macintosh.
И вот теперь, Claris переместил свой продукт на территорию Microsoft — обширный рынок Windows — в надежде повторить свой успех.
Claris Works 1.0 для Windows — блестящий продукт, приносящий отличное наследие Mac, вплоть до его модной иконки. В то время как новейшая версия MS-Works для Windows требует до 13 Мбайт вашего жесткого диск, полная установка Claris Works требует 4 Мбайт.
В отличие от Microsoft Works, которая в своих версиях для DOS, Mac или Windows основывается на отдельных элементах для каждого типа приложений, Claris Works сосредоточена на документах… один документ может предусматривать, например, обработку текстов, графики и электронных таблиц. Тогда как Microsoft использует буфер обмена для перемещения информации из файла электронной таблицы в файл текстового документа, документ Claris Works и ЯВЛЯЕТСЯ электронной таблицей.
Вы добавляете фрейм для графики, фрейм для текста, фрейм для электронной таблицы… строка меню меняется, чтобы отобразить текущий активный фрейм. А это позволяет создавать удивительно сложные документы.
Поскольку текстовый редактор поддерживает несколько столбцов и фреймы связанного текст, позволяя вам также работать с графическими инструментами, Вы можете использовать его для многих базовых DTP.
Таблица по размеру ограничена… только 500 на 40 (столбцов и строк), но его 100 функций по-прежнему обеспечивают значительную юзабилити. Семь основных стилей построения графиков включают в себя несколько стильных 3D эффектов. В отличие от второй версии MS-Works (но не новейшей третьей версии MS-Works для Windows), вы можете миксовать и сочетать шрифты, размеры и стили в одной таблице.
База данных — уменьшенная версия FileMaker Pro от Claris, — которая доступна также в версиях для Mac и Windows, проста в использовании. Вы можете начать с ввода имен полей и перетаскивания их вокруг, чтобы создать форму для ввода данных. База данных может быть объединена с текстовым редактором для слияния почты.
Особенно приятен в этой программе импорт файлов. Возможно не только импортировать разнообразные типы файлов Mac и ПК, но и открыть импортированный файл, просто перетаскивая иконку из диспетчера файлов в открытое окно Claris Works. К сожалению, единственный формат, который не возможно импортировать — файлы, созданные в Claris Works версии 2.0 для Mac. Удивительно, но факт.
В версии для Windows (в отличие от версии для Mac) отсутствует модуль обмена сообщениями, зато используется программа Windows Terminal. Если вы, как и я, давно удалили маломощный Terminal, то тут вам не повезло. Microsoft заметила недостаток, добавив новейшими MS-Works более сочный модуль обмена сообщениями.
Windows позволяет легко создавать составные документы… файлы, объединяющие по мере необходимости текст, электронные таблицы, базу данных и графику. Это легко, если у вас есть 40-100 Мбайт последних приложений, и вы научились использовать их все. Это часть уговора касательно недавней моды на пакет программ от одной компании.
Но при том, что большинство пользователей используют в действительности только 10-25% возможностей этих высококлассных приложений, есть еще местечко для программ «Works» поскромнее.
Claris Works не только заняло данную товарную нишу в Mac… в Windows это небольшое приложение с до фига индивидуальности и дерзости. Claris с радостью разошлет бесплатную рабочую модель; оно заслуживает серьезного внимания ввиду его уникального подхода.
(Примечание за 2003 год). Вышеупомянутая статья была первоначально опубликована в 1994 году в качестве обзора. Десять и более лет спустя я получил серию писем от фанов, надеющихся, что я смогу продать им копию этого программного обеспечения или направить их туда, где оно все еще доступно. Хотя я и делал обзоры на программное обеспечение с 1991 года, я не являюсь поставщиком каких-либо товаров. Я советую всем, кто ищет копии старого программного обеспечения, поискать его на eBay или на OldSoftware.com. Если вы зайдете на мои веб-страницы Files, вы найдете ссылки на ряд (в основном бесплатных) программ, которые можно загрузить — некоторые из них могут стать хорошей заменой для более старых программ.

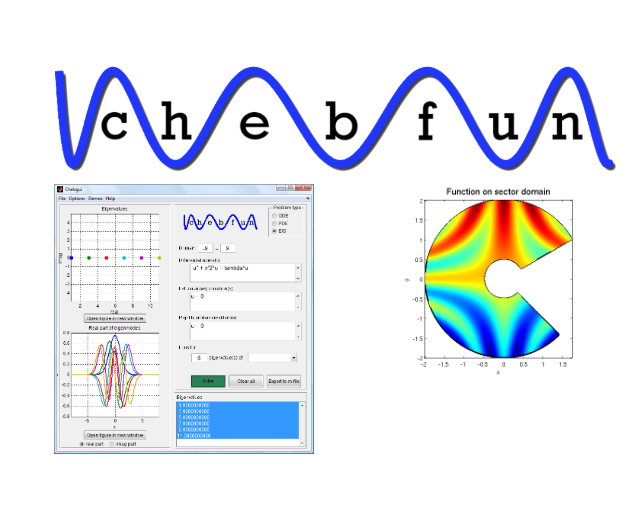 Его цель состоит в том, чтобы обеспечить численное вычисление с функциями. Мой интерес и вклад в систему наиболее заметен в решении обыкновенных и (1+1 мерных) дифференциальных уравнений в частных производных. Используя знакомый синтаксис MATLAB, такой как \ и eigs, решения краевых или собственных задач могут быть получены с полной числовой точностью автоматически.
Его цель состоит в том, чтобы обеспечить численное вычисление с функциями. Мой интерес и вклад в систему наиболее заметен в решении обыкновенных и (1+1 мерных) дифференциальных уравнений в частных производных. Используя знакомый синтаксис MATLAB, такой как \ и eigs, решения краевых или собственных задач могут быть получены с полной числовой точностью автоматически. конформными отображениями областей, ограниченных полигонами, включая неограниченные области, логические четырехугольники и каналы. Он включает в себя модуль для решения уравнения Лапласа в таких областях с кусочно-постоянными граничными условиями, до десяти и более цифр в секундах. Почти все функции Toolbox доступны через графический интерфейс.
конформными отображениями областей, ограниченных полигонами, включая неограниченные области, логические четырехугольники и каналы. Он включает в себя модуль для решения уравнения Лапласа в таких областях с кусочно-постоянными граничными условиями, до десяти и более цифр в секундах. Почти все функции Toolbox доступны через графический интерфейс.